Mazes for Programmers: Dijkstra's algorithm
December 26, 2019
Related post: mazes for programmers: binary tree and sidewinder
In mazes for programmers: binary tree and sidewinder we explored several techniques for generating mazes by interconnecting the cells of a grid and then treating those interconnections as paths between the cells.
Round 2 of Mazes for Programmers has us implementing Dijkstra’s algorithm to solve a maze by finding the shortest path between two points using the notion of cost.1
As a side-effect, one also gets pretty good at typing “Dijkstra”.
The algorithm in a nutshell:
- Determine the starting point of the grid (commonly the northwestern-most cell).
- Record the cost of reaching that cell: 0.
- Find that cell’s navigable neighbors.
- For each neighbor, record the cost of reaching the neighbor: 1.
- For each neighbor, repeat steps 3-5, taking care not to revisit already-visited cells.
When complete, we’ll have a record of the cost of reaching each cell iteratively from the starting point. This data tells us how far each cell is from the root, and you can imagine this being perfectly useful in its own right.
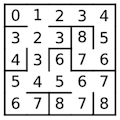
If we now traverse that body of data with cost information in reverse, starting from the desired endpoint and stepping through cells that bear a cost less than the cost of the current cell, we’ll eventually reach the root cell via the shortest path possible.

Because our maze generator currently outputs only perfect mazes, with exactly one path between any two points, the shortest path from start to end is also the only path from start to end, but you can imagine more complicated mazes with multiple ways to reach the goal cell.
You can also imagine a more realistic terrain where costs differ depending on the realities of any given point; perhaps climbing a mountain pass or traversing a forest is time-consuming, or takes the traveller too far away from water sources. Finding the shortest (or least-expensive, or safest, or etc.) path between any two cells is easily obtained via the same algorithm by having additional information for each cell informing that cell’s cost; the steps above describe a cost of 1 for simplicity’s sake alone.
Ruby Dijkstra
The Ruby implementation was a short-lived stop on my way to Clojure side of things; after studying the book’s implementation for a bit, I folded it in, preserving my own local variances for seeding and debugging and quickly moved on.
Clojure Dijkstra
The Clojure implementation is where things get interesting. Thus far we’ve established some patterns around maze generation and display, and we’ll be able to use those again here (and having used this boilerplate three times with minimal tweaks, it’s due to be factored out into a shared implementation).
However, actually solving a maze means new kinds of work need to be accomplished:
- We’ll need to actually walk the maze in order to solve it, which means…
- Cells will need two-way links so that we can walk paths in reverse.
- We’ll have to find the shortest path, which means….
- We’ll have to determine cell costs.
In previous maze generation work, I concentrated on keeping the grid structure as minimal as possible, using one-way links to determine paths, but in finding the shortest path back from the goal cell, we’ll now have to walk the cells backwards, and this is more easily done if links are reciprocal.
For generation I had also avoided making much use of embedding coordinates in the cells themselves, relying mostly on the nested list-of-lists shape to drive display, but given the data structure I chose to use for solving, relying on those coordinates more made downstream processing simpler.
Spoiler alert: looking back, it’s clear that my instinctive choice to use a single data structure by overloading it with information for completing all these tasks was less than ideal; the code would have been much simpler by using several smaller, task-focused data structures to attack the various sub-problems piecemeal.
Warning signs include: having to do too much work to re-shape the data structure for ephemeral tasks, a mix of helper functions that work with coordinates and ones that work with shape, and too much damn code.
I’d like to take another pass and tighten it up, but for now…

It does the thing. Which is nice.

There are other ways to make this more interesting – path priority using the A* algorithm to avoid exploring non-goal paths, using non-perfect mazes with multiple ways to reach the goal, but the thing I’d really like to do here is lift this into some kind of UI with a stepper control so the maze can be solved (and un-solved) incrementally.
Until next time!
-
As an aside, I found this bit from the Wikipedia article interesting: “we sat down on the café terrace to drink a cup of coffee and I was just thinking about whether I could do this, and I then designed the algorithm for the shortest path… One of the reasons that it is so nice was that I designed it without pencil and paper. I learned later that one of the advantages of designing without pencil and paper is that you are almost forced to avoid all avoidable complexities.” This seems insightful because I think of pencil and paper as a secret weapon when I’m working through a problem but am too close to the code and need to regroup, but hadn’t considered its own relationship to tool-free rumination (“hammock time”, or as I tend to think of it, “shower time”) as yet another step up the very same power continuum. ↩